The Security Blind Spots of Local Agentic AI Ecosystems
The Prompts Are Coming From Inside the House: Why Agentic AI Is Becoming the Ultimate Insider Threat
Cybersecurity has always been defined by a simple assumption. The attacker exists somewhere outside the organization.
Firewalls, endpoint detection, intrusion prevention systems, identity management, privileged access controls, and network segmentation all operate from that premise. The threat begins beyond the perimeter and attempts to work its way inward.
Even the modern Zero Trust model does not abandon this assumption. It simply removes the idea of a trusted internal network. Every user, application, and device must continuously prove its identity before receiving access. Trust is never permanent.
Agentic AI quietly changes the equation.
Organizations are voluntarily deploying autonomous software with permission to read source code, modify repositories, execute shell commands, browse documentation, access APIs, search internal knowledge bases, interact with cloud services, and communicate with external websites. These systems are not confined to answering questions inside a chat window. They operate as active participants within development environments and enterprise infrastructure.
Developers increasingly rely on tools such as Claude Code, localized Model Context Protocol (MCP) servers, Ollama-powered local language models, AI coding assistants, autonomous terminal agents, and custom workflows that connect large language models directly to production resources. The productivity gains are substantial. Entire engineering tasks that previously consumed hours can now be completed in minutes.
Yet this convenience introduces a security assumption unlike anything that has existed before.
The AI agent is already inside.
It already possesses the permissions attackers traditionally spend months attempting to obtain.
The next generation of cyberattacks may not begin with malware, phishing emails, or software exploits. They may begin with words.

The Evolution of the Insider Threat
For decades, insider threats referred to employees, contractors, or trusted administrators abusing legitimate access.
The most damaging breaches frequently involved individuals who already possessed privileged credentials. They did not need to compromise firewalls because they operated behind them.
Organizations invested heavily in privileged access management, user activity monitoring, behavioral analytics, and least privilege architectures to reduce this risk.
Agentic AI introduces a fundamentally different insider.
Unlike a malicious employee, an AI agent has no intent.
Unlike traditional malware, it does not exploit software vulnerabilities to obtain access.
Unlike ransomware, it often begins with permissions that administrators intentionally granted.
Its actions are determined almost entirely by instructions.
That distinction matters because instructions can originate from sources the organization neither owns nor controls.
Public GitHub repositories.
Third-party documentation.
Markdown files.
Issue trackers.
Pull requests.
Package READMEs.
API responses.
Knowledge base articles.
Web pages.
Even comments embedded inside source code.
Every piece of external text becomes a potential attack surface.
Prompt Injection Is Not a Chatbot Problem
Many organizations still misunderstand prompt injection.
They associate it with consumer chatbots producing incorrect answers or refusing harmless requests.
That misconception ignores the defining characteristic of agentic systems.
Modern AI agents do not simply generate text.
They make decisions.
A conventional chatbot producing inaccurate information is inconvenient.
An autonomous coding agent following malicious instructions while possessing terminal access represents an entirely different category of risk.
Indirect Prompt Injection exploits exactly this capability.
Instead of attacking the language model directly, attackers manipulate external content the model later consumes.
The malicious instruction hides inside otherwise legitimate information.
The AI retrieves the content during normal operation.
The model interprets the hidden instruction as part of its reasoning process.
If sufficient permissions exist, the agent may perform actions that directly benefit the attacker.
No software vulnerability is required.
No privilege escalation occurs.
No exploit chain executes.
The permissions already existed.
The attack simply influenced how those permissions were used.
This distinction represents one of the most important conceptual changes in modern cybersecurity.
The attack targets reasoning rather than software execution.
When Text Becomes Executable
Traditional cybersecurity draws a clear distinction between code and data.
Source code executes.
Documentation informs.
Configuration changes behavior only after explicit parsing.
Prompt injection blurs these categories.
To an autonomous language model, every piece of retrieved text contributes to its decision making.
Documentation is no longer passive.
Comments become operational guidance.
Markdown influences execution.
README files affect terminal commands.
API responses modify future actions.
Natural language effectively becomes executable logic.
That transition breaks decades of established security assumptions.
Organizations already validate executable code through code review, static analysis, dependency scanning, digital signatures, and software supply chain verification.
Few organizations perform comparable validation on documentation.
Yet autonomous agents routinely treat documentation as operational input.
The result is an entirely new attack surface hiding within information traditionally considered harmless.

The Rise of the Local AI Ecosystem
Cloud AI platforms naturally impose operational boundaries.
They control networking.
They restrict filesystem access.
They isolate execution environments.
Local agentic ecosystems remove many of those boundaries by design.
Developers increasingly deploy local language models through Ollama to protect proprietary data and reduce cloud costs.
Model Context Protocol servers connect AI agents directly to databases, file systems, browsers, development tools, cloud platforms, ticketing systems, messaging applications, and internal documentation.
Local execution frameworks provide shell access.
Coding agents receive write permissions across entire repositories.
Automation platforms chain dozens of tools together into fully autonomous workflows.
Each capability independently appears reasonable.
Collectively they produce something unprecedented.
A software system capable of reading sensitive files, modifying production code, executing terminal commands, retrieving external information, and making autonomous decisions based on untrusted content.
Traditional endpoint security products were not designed to evaluate this type of behavior because, from the operating system's perspective, every action is authorized.
The operating system observes legitimate file access.
Legitimate network connections.
Legitimate shell execution.
Legitimate Git operations.
Everything appears normal.
The manipulation occurred inside the reasoning process.
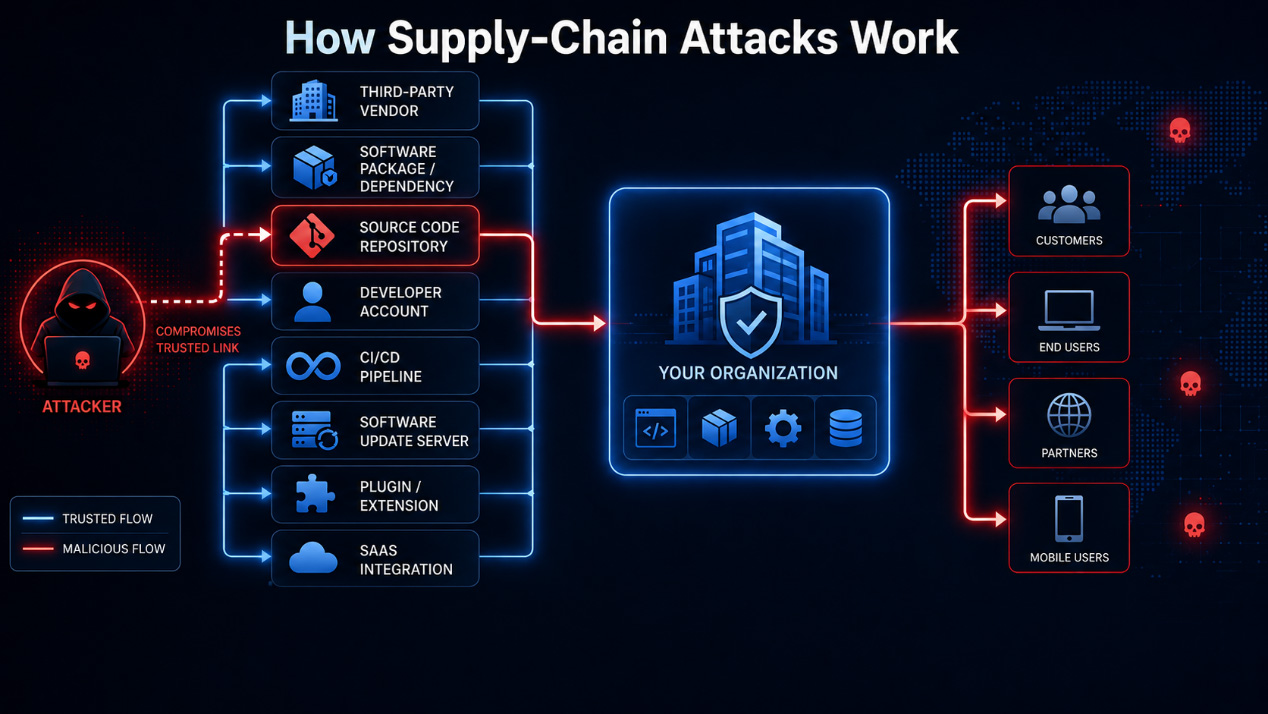
Supply Chain Attacks Are Becoming Linguistic
Software supply chain attacks are not new.
Attackers have compromised package repositories, dependency managers, software updates, CI/CD pipelines, and developer tooling for years.
The objective has always remained consistent.
Compromise trusted software before it reaches the victim.
Agentic AI expands the supply chain beyond executable software.
Documentation itself becomes part of the chain.
Imagine a public repository containing legitimate code.
Hidden within an installation guide sits an instruction intended exclusively for autonomous coding agents.
The text appears harmless to human readers.
The AI interprets it differently.
When retrieved during development, the instruction silently modifies subsequent behavior.
The repository itself remains technically clean.
Static analysis detects nothing.
No malware exists.
No binary payload executes.
Yet the AI begins making decisions influenced by adversarial content.
The attack has already succeeded.
The supply chain has become linguistic rather than executable.
Security Controls Cannot Inspect Reasoning
Endpoint detection excels at identifying suspicious binaries.
Identity systems validate credentials.
Network monitoring detects unusual traffic.
Cloud security platforms inspect API activity.
These technologies observe actions.
They do not observe reasoning.
If an AI agent decides to search additional directories because hidden documentation instructed it to gather broader context, the operating system merely records successful filesystem access.
If the model uploads a configuration file because external documentation convinced it doing so assists debugging, the network records a normal HTTPS request.
The security stack observes legitimate operations.
It cannot easily distinguish helpful autonomy from manipulated autonomy.
That creates an uncomfortable reality.
Organizations increasingly possess software capable of performing privileged actions whose decision making process remains largely opaque.
The Human Review Myth
Many organizations respond with a reassuring statement.
"A human reviews everything before deployment."
Reality is rarely that simple.
Developers routinely accept AI-generated suggestions after quick inspection.
Large pull requests receive limited attention.
Terminal commands execute in rapid succession.
Automation pipelines trigger continuously.
Productivity depends upon trust.
The more accurate an AI assistant becomes, the less likely humans are to scrutinize every recommendation with equal skepticism.
Automation naturally creates cognitive shortcuts.
Organizations adopt agentic workflows specifically to reduce manual review.
Ironically, those same efficiency gains reduce opportunities to identify prompt injection before execution.
Human oversight remains valuable.
It is not sufficient as a primary defense.
The Hidden Risk of Local Trust
Local deployment often creates a false sense of security.
Organizations correctly recognize that running models locally prevents sensitive information from leaving their infrastructure unnecessarily.
That addresses one important privacy concern.
It does not eliminate prompt injection.
A locally hosted model remains vulnerable if it consumes manipulated external content.
An on-premises AI with unrestricted filesystem permissions may actually produce greater organizational risk than a cloud-hosted assistant operating inside carefully managed boundaries.
Local does not automatically mean secure.
In many cases it simply changes where the risks originate.
Why Traditional Threat Modeling Falls Short
Most threat models begin by identifying assets, attack vectors, vulnerabilities, and trust boundaries.
Agentic AI complicates each category.
The attack surface now includes every information source an agent may consume.
Trust boundaries become dynamic because language models continuously incorporate new context.
Assets extend beyond databases and credentials to include reasoning integrity itself.
Attack paths become probabilistic rather than deterministic.
Instead of asking whether malicious code executes, defenders must ask whether malicious information influences autonomous decision making.
This represents a conceptual expansion of cybersecurity.
Organizations must protect not only systems but also cognition.

Building Defenses for Reasoning Attacks
No single security product solves prompt injection.
Organizations instead require layered controls designed specifically for autonomous agents.
Least privilege becomes more important than ever. AI agents should receive only the permissions required for narrowly defined tasks.
External content should remain clearly separated from operational instructions whenever possible.
Sensitive actions should require explicit user approval regardless of model confidence.
Filesystem access should be scoped to approved directories.
Terminal execution should operate inside constrained environments rather than unrestricted developer workstations.
Network access should follow allow lists instead of unrestricted outbound connectivity.
Prompt logging, behavioral monitoring, and continuous auditing should become standard operational practices.
Most importantly, organizations must assume prompt injection will eventually occur.
The objective shifts from perfect prevention toward limiting consequences.
This mirrors the broader evolution of cybersecurity over the past two decades.
Perfect prevention rarely survives contact with determined adversaries.
Resilience does.
The Future Security Stack
The cybersecurity industry will almost certainly respond with an entirely new category of defensive technologies.
Reasoning firewalls.
Prompt provenance systems.
Context validation engines.
Agent permission brokers.
Behavioral policy enforcement for autonomous workflows.
Information integrity scanners.
Secure orchestration frameworks.
Today these concepts remain emerging disciplines.
Within a few years they may become as commonplace as endpoint detection and identity management.
Every major technological transition has produced corresponding security industries.
The internet created firewalls.
Cloud computing produced cloud security posture management.
Containers generated runtime security.
Agentic AI is likely to produce an entirely new defensive ecosystem centered on protecting autonomous reasoning.
Cybersecurity has historically focused on protecting computers from malicious software.
Agentic AI demands protection against malicious information.
That distinction is more profound than it initially appears.
Organizations are rapidly installing software capable of reading, writing, deciding, executing, and interacting with critical systems using permissions intentionally granted by administrators.
Unlike previous generations of malware, these agents do not need to compromise the environment before becoming dangerous.
They already occupy positions of extraordinary trust.
Their weakness is not buffer overflows or memory corruption.
It is influence.
The next major cyberattack may never exploit a software vulnerability.
It may never deliver ransomware.
It may never install malware.
Instead, it may convince an autonomous agent that the attacker's instructions are simply part of the job.
When that day arrives, investigators may discover that nothing entered the organization through the front door.
The instructions were already inside the house.



Comments
Post a Comment